1. 两数之和
大数据实时主流信息查询
为解决大数据实时主流信息查询的需求,采用python技术,设计了实时主流信息程序,获得了满意的结果,程序经测试,符合预期需求,为构建一种可以灵活扩展的应用程序提供解决思路或借鉴。
3. 
\程序设计:**

cmd = 'your command'
res = subprocess.call(cmd, shell=True, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
用于隐藏cmd命令窗口
打包时需要pyinstaller --onefile --icon=favicon.ico test.py -w
普通的pyinstaller -F -i favicon.ico test.py
无法隐藏cmd命令窗口
window = tk.Tk()
创建gui
window.title("LHL's Information")
window.iconbitmap('favicon.ico')
window.geometry("1500x1000")
设置窗口名称,图标,大小
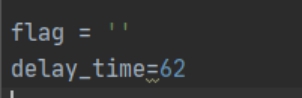
这两个为全局变量
Flag表示现在的线程 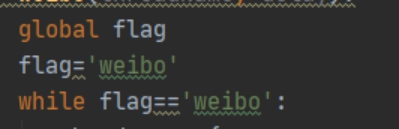
用于控制临界资源,不抢占text输出窗口
delay_time
为time.sleep的时间,单位秒
定义定义线程刷新时间间隔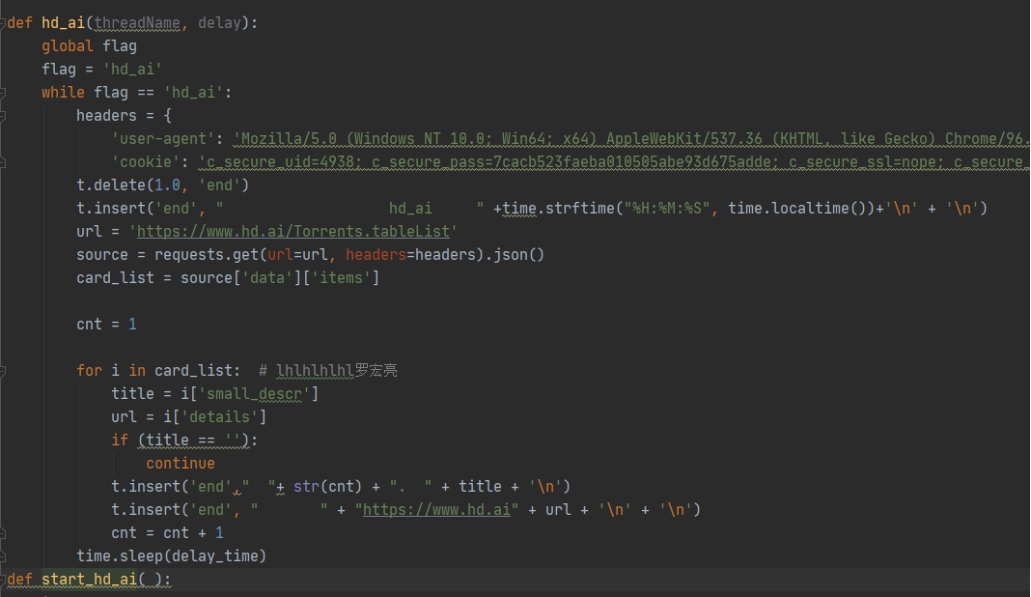
\Flag一定要用全局,不然无法起到控制临界资源的作用**
HTTP是“Hypertext Transfer Protocol”的所写,整个万维网都在使用这种协议,几乎你在浏览器里看到的大部分内容都是通过
http协议来传输的.
HTTP Headers是HTTP请求和相应的核心,它承载了关于客户端浏览器,请求页面,服务器等相关的信息。
'user-agent':
User-Agent会告诉网站服务器,访问者是通过什么工具来请求的,如果是爬虫请求,一般会拒绝,如果是用户浏览器,就会应答。
'cookie':
Cookie是保存在客户端的纯文本文件。比如txt文件。所谓的客户端就是我们自己的本地电脑。当我们使用自己的电脑通
过浏览器进行访问网页的时候,服务器就会生成一个证书并返回给我的浏览器并写入我们的本地电脑。
t = tk.Text(window, width=3840, height=2160, font=('Consolas', 15))
创建一个文本框输出输出
t.delete(1.0, 'end') 为删除之前显示的内容
t.insert('end', " hd_ai" + '\n' + '\n')
插入标题
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式
url = 'https://www.hd.ai/Torrents.tableList'
source = requests.get(url=url, headers=headers).json()
请求json数据
#### card_list = source['data']['items']
#### 定位到每个词条
Card_list中包含所有的词条,是一个集合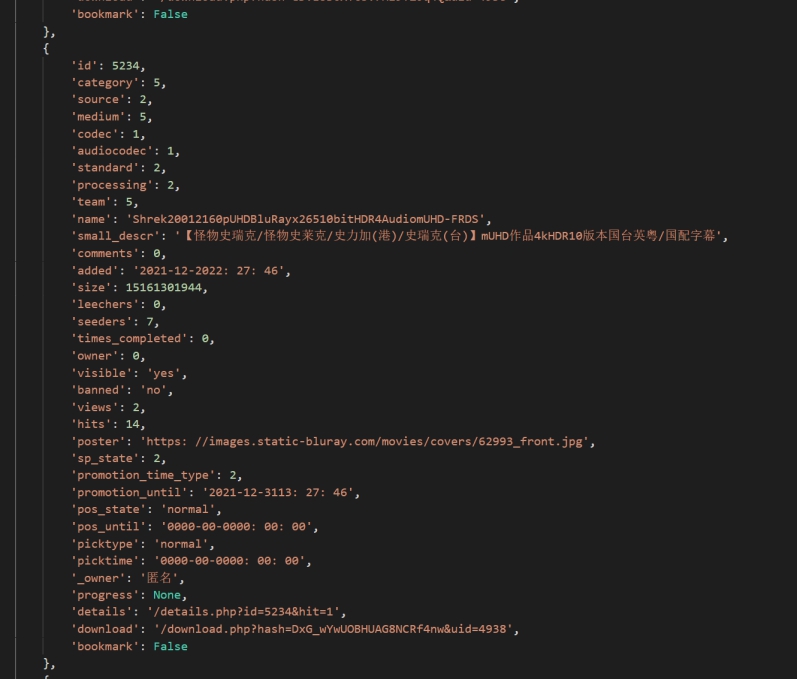
之后遍历card_list下的'small_descr'和'details' 得到标题和网址
之后通过t.insert 输出到tk.Text
除了上面json按层级展开,还有xpath寻找和正则表达式寻找

titles = tree.xpath('//*[@id="sanRoot"]/main/div[2]/div/div[2]/div')
为匹配到所用的div词条
for i in titles:
再进行逐个遍历输出词条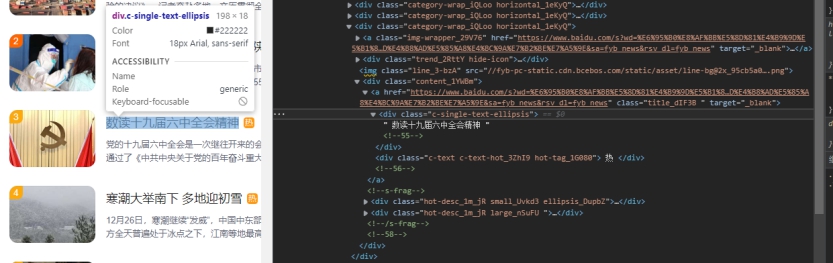 ```
```
再输出想要的数据到tk.text后
操作菜单', 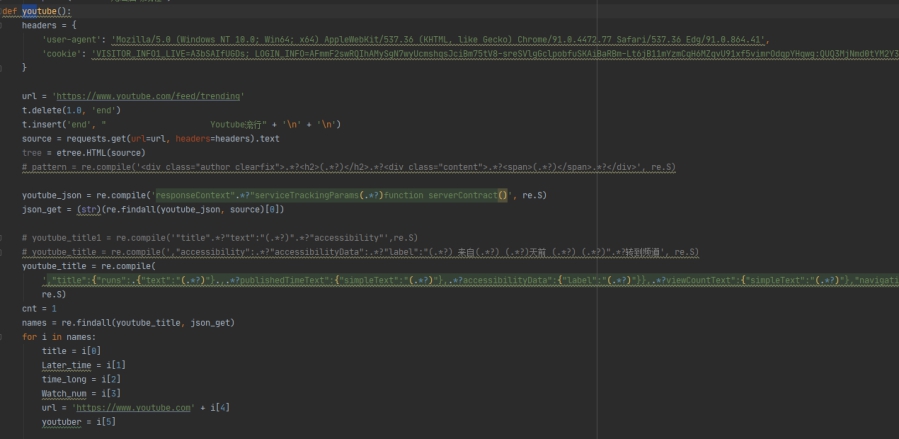
Youtube 的结构比较复杂,需要用到正则匹配
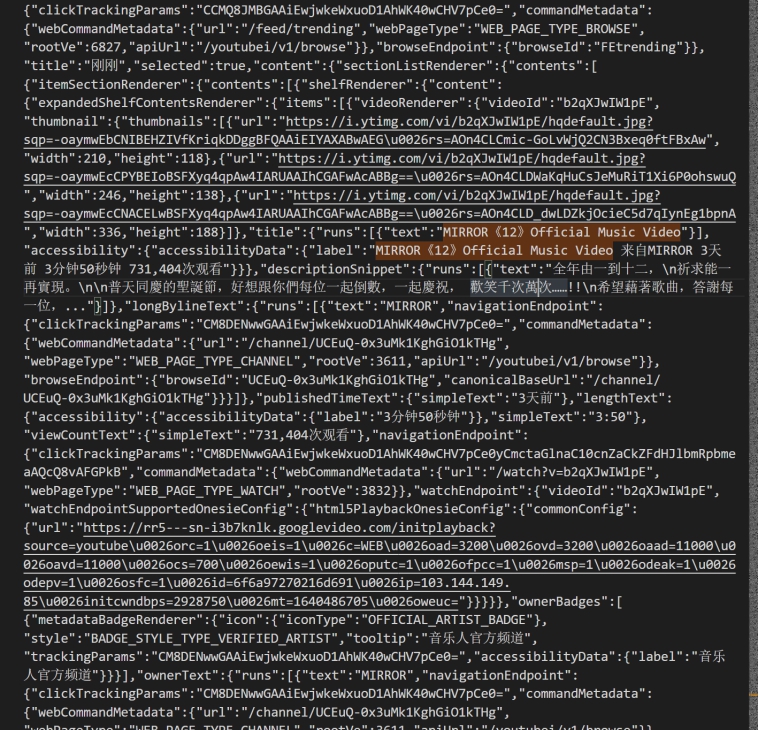
youtube_json = re.compile('responseContext".*?"serviceTrackingParams(.*?)function serverContract()', re.S)
(.*?)为需要的内容 .*?为可以变动的内容 其他为固定内容因为内容太多,匹配需要很长时间,先进行一次筛选,只留下包含信息的内容
再进行第二次筛选youtube_title= = re.compile(',"title":{"runs":.{"text":"(.*?)"}.,.*?publishedTimeText":{"simpleText":"(.*?)"},.*?accessibilityData":{"label":"(.*?)"}},.*?viewCountText":{"simpleText":"(.*?)"},"navigationEndpoint.*?webCommandMetadata.*?url":"(.*?)".*?ownerText.*?text":"(.*?)","navigationEndpoint.*?操作菜单',re.S)
names = re.findall(youtube_title, json_get)
用youtube_title规则对 json_get 进行筛选
得到 6 条有用信息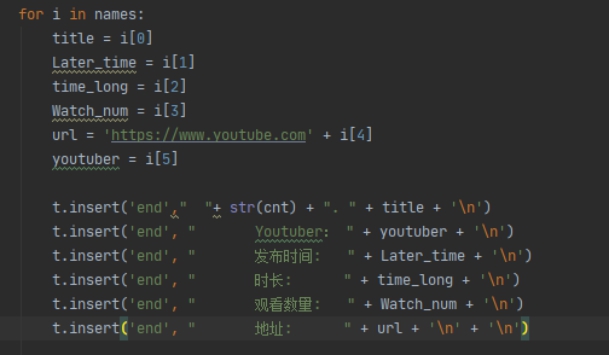
再进行输出,得到结果
threadName, delay 是用于多线程的名字和延迟,但我的延迟不由此决定,而是由time.sleep(delay_time)决定
Delay_time是一个全局变量,方便全局控制,无需逐个调试
每个功能都用一个线程调用
flag = 'hd_ai'
while flag == 'hd_ai':
上面的flag用于控制临界资源,就是Tk.text
如果多个线程调用text,则他们抢占text,无法看清内容
如果不用多线程的话,就会出现
如果网页请求超时或无法请求或网页格式改变,程序就会卡死,无响应\程序******运行界面****
 |
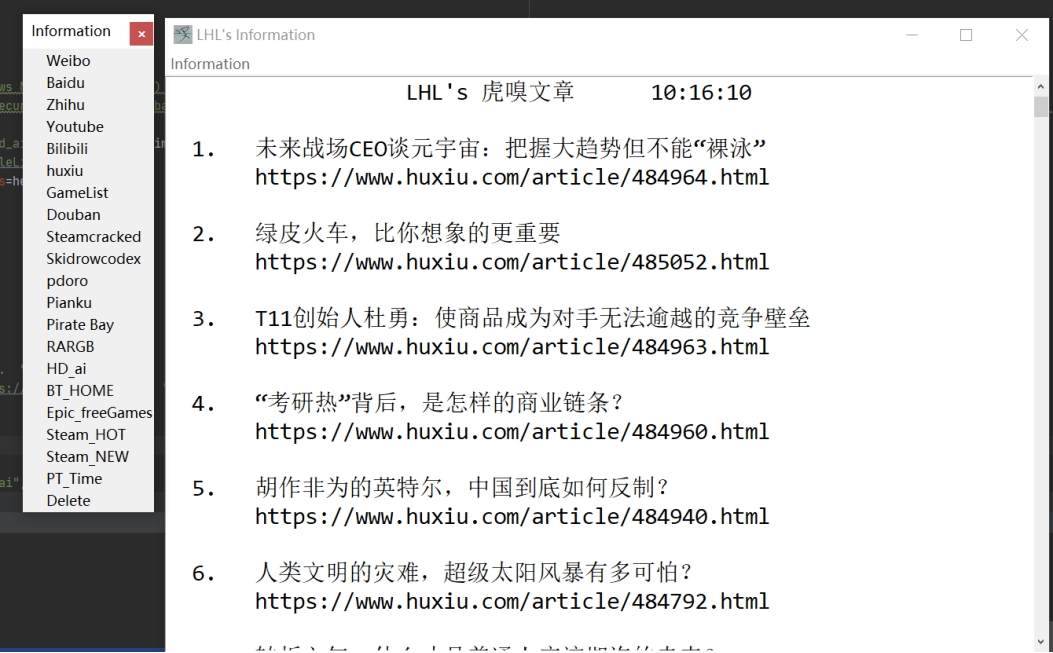

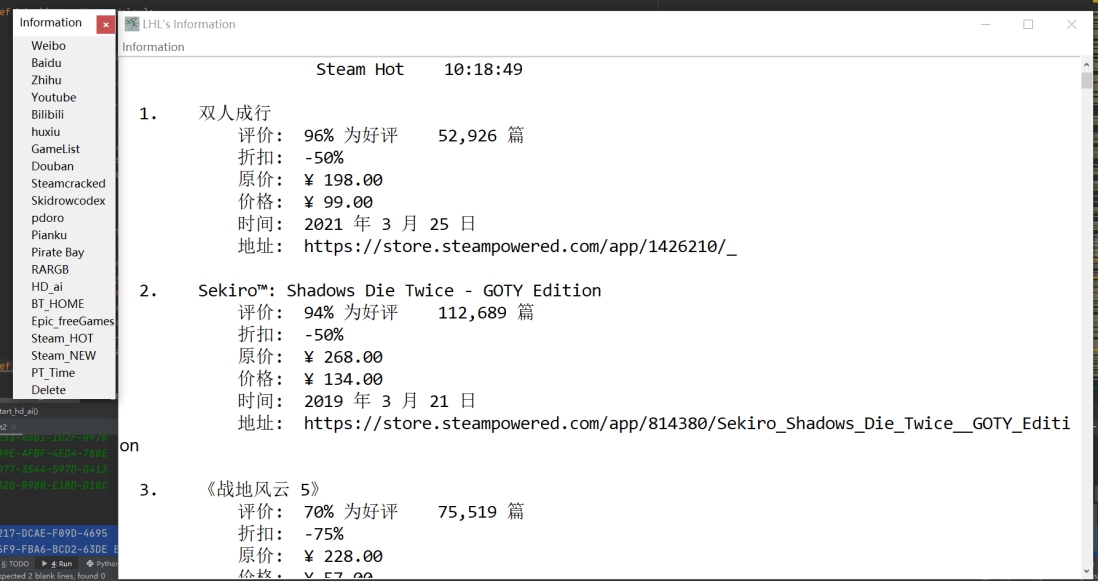
结论与感想
大数据技术用了多年时间进行演化,才从一种看起来很炫酷的新技术变成了企业在生产经营中实际部署的服务。其中,数据采集产品迎来了广阔的市场前景,无论国内外,市面上都出现了许多技术不一、良莠不齐的采集软件。一款简单易用的网页信息抓取软件,能够抓取网页文字、图表、超链接等多种网页元素。同样可通过简单可视化流程进行采集,服务于任何对数据有采集需求的人群。
一个简单,简洁的信息搜集软件对我生活的改变是巨大的,不用花大量的时间在互联网上寻找新闻与信息,只需要简单的浏览,便可以知道绝大多数想了解的信息,从而提高效率,获得更多的信息。
软件往往无需过度的修饰,斯是陋室,惟实用,为先,简单往往意味着高效。过度的修饰往往破坏获取信息的效率。互联网的信息过于繁杂,往往只需要获取头部的信息,和一些深度分析文章即可。
要主动打破信息茧房,不要让算法左右了我们的人生。


